인덱스란 검색 속도를 높이기 위한 색인 기술이다.
일반적으로 SELECT의 WHERE에 사용할 컬럼을 효율적으로 검색하거나 다른 테이블과의 JOIN에 사용된다.
DB 테이블에는 INDEX가 없는 경우 처음 레코드부터 마지막 레코드까지 풀 스캔(Full Scan) 하게 된다.
이때, 검색 속도 향상을 이유로 인덱스를 사용하게된다.
Index 설정기준
- 카디널리티가 높은 컬럼(한 컬럼이 가지고있는 중복도가 낮음을 의미)
- 선택도가 낮다(한 컬럼이 가지고있는 값 하나로 적은 row만 찾아진다, *선택도: 5~10%)
- 수정 빈도가 낮은 컬럼
- WHERE에 자주 사용되는 컬럼
- ORDER BY에 자주 사용되는 컬럼
- JOIN에 자주 사용되는 컬럼
- LIKE 사용할경우 %가 뒤에 사용되도록하기
* 선택도 계산법( 컬럼 특정 값 row / 테이블 총 row * 100)
ex) 총 10 row에서 고유 학번(grade), 2명의 같은 이름(name), 5명의 같은 나이(age)
1. 학번(grade) 컬럼 선택도 - 1 / 10 = 10%
2. 이름(name) 컬럼 선택도 - 2 / 10 = 20%
3. 나이(age) 컬럼 선택도 - 5 / 10 = 50%
테이블 정보 및 사용 쿼리 수집
User
create table users (
id BIGINT PK
name VARCHAR,
point BIGINT,
create_at DATETIME,
update_at DATETIME,
primary key (id)
)User - 사용 쿼리
// 1. 사용자 조회
SELECT * FROM users
WHERE id = #{id};
// 2. 포인트 충전/사용
UPDATE users SET
point = #{point}
WHERE id = #{id};Cart
create table cart (
id BIGINT PK,
userId BIGINT,
create_at DATETIME,
update_at DATETIME,
primary key (id)
)Cart - 사용 쿼리
// 1. 카트 조회
SELECT * FROM cart
WHERE userId = #{userId}
// 2. 카트 생성
INSERT INTO cart (user_id, created_at, updated_at)
VALUES (?, ?, ?);CartItem
create table cart_item (
id BIGINT PK,
cart_id BIGINT,
product_id BIGINT,
quantity BIGINT,
create_at DATETIME,
update_at DATETIME,
primary key (id)
)CartItem - 사용 쿼리
// 1. 장바구니 추가
INSERT INTO cart_item (cart_id, product_id, quantity, created_at, updated_at)
VALUES (?, ?, ?, ?, ?);Product
create table product (
id BIGINT PK,
name varchar(255),
price BIGINT,
create_at DATETIME,
update_at DATETIME,
primary key (id)
)Product - 사용 쿼리
// 1. 상품 상세
SELECT *
FROM product
WHERE id = {productId}
// 2. 상품 리스트
SELECT *
FROM product
// 3. 주문신청 상품정보
SELECT
p.id, p.name, p.price, ps.stock
FROM ProductEntity p
LEFT JOIN ProductStockEntity ps
ON p.id = ps.productId
WHERE p.id IN :productIds
// 4. 최근 3일간 인기상품 조회
SELECT
p.name, SUM(oi.quantity)
FROM ProductEntity p
JOIN OrderItemEntity oi
ON p.id = oi.product_id
WHERE oi.create_at BETWEEN :startDate AND :endDate
ORDER BY SUM(oi.quantity) DESC
GROUP BY oi.product_idProductStock
create table product_stock (
product_id BIGINT PK,
stock BIGINT,
create_at DATETIME,
update_at DATETIME,
primary key (product_id)
)ProductStock - 사용 쿼리
// 1. 상품재고 조회
SELECT * FROM product_stock
WHERE product_id = #{id}
// 2. 상품재고 수정
UPDATE product_stock SET
WHERE product_id = #{id}Order
create table orders (
id BIGINT PK,
user_id BIGINT,
create_at DATETIME,
update_at DATETIME,
primary key (id)
)Order - 사용 쿼리
// 1. 주문 생성
INSERT INTO order (user_id, created_at, updated_at)
VALUES (?, ?, ?)OrderItem
create table order_Item (
id BIGINT PK,
order_id BIGINT,
product_id BIGINT,
quantity BIGINT,
create_at DATETIME,
update_at DATETIME,
primary key (id)
)OrderItem - 사용 쿼리
// 주문 상품 저장
INSERT INTO order_item (order_id, product_id, quantity, created_at, updated_at)
VALUES (?, ?, ?, ?, ?)
주요 쿼리 및 개선
- 최근 3일간 인기 판매상품(인덱싱 전)

- 쿼리 응답시간
test_db > SELECT
p.name,
SUM(oi.quantity)
FROM
product p
JOIN order_item oi
ON p.id = oi.product_id
WHERE oi.create_at BETWEEN '2024-11-11 10:36:06.221586' AND '2024-11-12 10:36:06.221586'
GROUP BY
oi.product_id
[2024-11-13 16:21:55] 43 rows retrieved starting from 1 in 32 ms (execution: 7 ms, fetching: 25 ms)
- 최근 3일간 인기 판매상품(인덱싱 후)
CREATE INDEX idx_order_item_create_at ON order_item (create_at);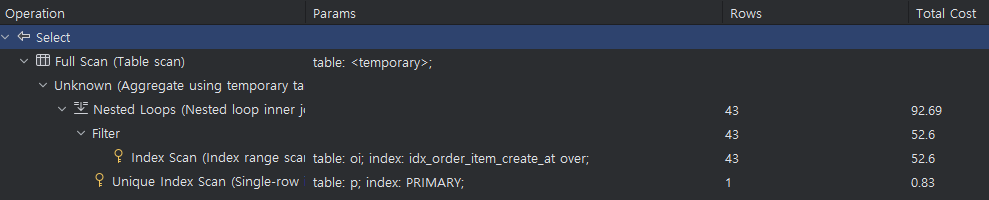
- 쿼리 응답시간
test_db > SELECT
p.name,
SUM(oi.quantity)
FROM
product p
JOIN order_item oi
ON p.id = oi.product_id
WHERE oi.create_at BETWEEN '2024-11-11 10:36:06.221586' AND '2024-11-12 10:36:06.221586'
GROUP BY
oi.product_id
[2024-11-13 16:22:07] completed in 2 msIndex 선정기준 1,2 를 만족한 주문아이템 생성시간(create_at)이 인덱스 컬럼으로 적합하다 판단했습니다.
기존에는 약 90만건의 테이블 풀 스캔하여 데이터를 가져왔다면 이후에는 범위만큼(range Index)만 데이터를 가져옵니다.
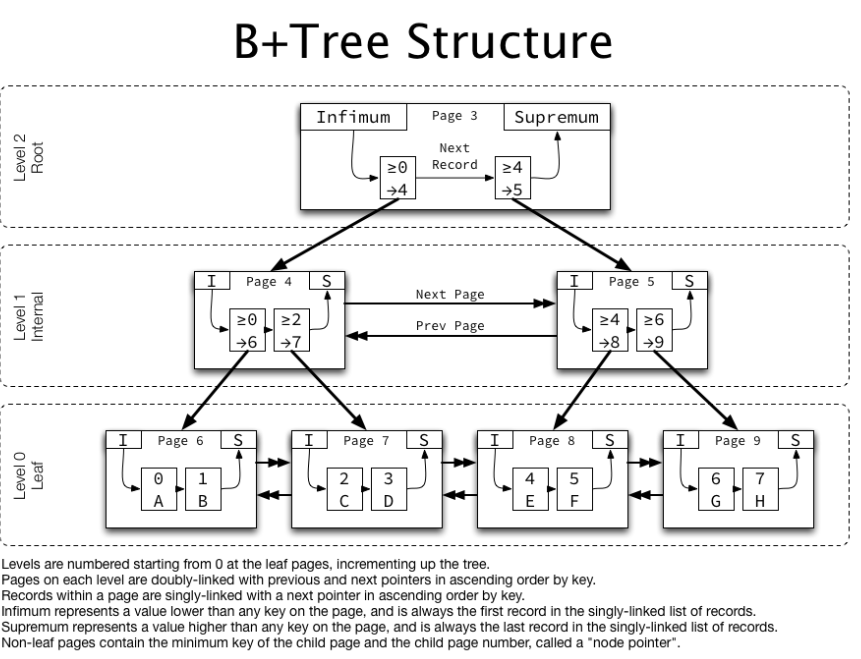
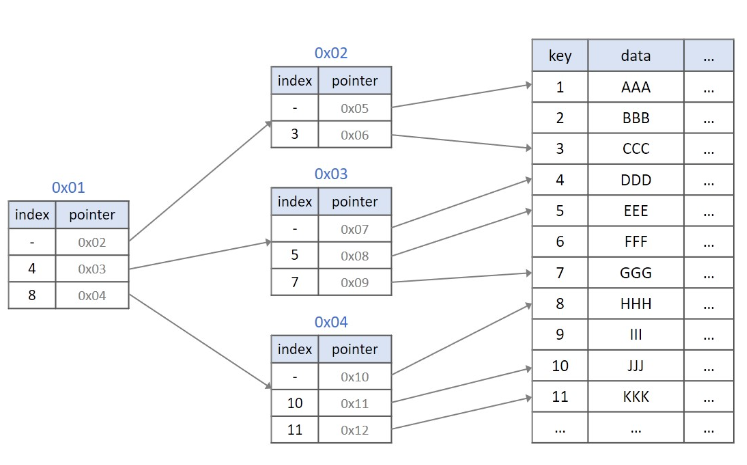
MySQL 8.0 기준 InnoDB 에서의 인덱스 자료구조는 B+Tree 입니다.
자식노드가 2개 이상인 B-Tree를 개선시킨 자료구조이며 특성은 다음과 같습니다.
- 리프노드만 인덱스와 함께 데이터를 가진다.
- 나머지 노드들은 데이터를 위한 인덱스(key)만 가진다.
InnoDB에서는 같은 레벨 노드끼리는 Double LinkedList로 연결, 자식 노드는 Single LinkedList로 연결됩니다.